
新乡凯发国际平台首页,k8凯发国际登录,K8凯发登录入口弹簧有限公司
专注生产各类弹簧三十余年
全国服务热线 18530710992
专注生产各类弹簧三十余年
全国服务热线 18530710992

18530710992
河南省辉县市学院路北段路西
近年★★◆■,投稿数量从三百多篇到近千篇,学者投稿 SIGGRAPH Asia 的热情正直线走高,不过■★,也有会场学者表达了些许遗憾◆◆★■,在他们看来,本次大会还是没有给到太多预期外的惊喜。
目前情况来看◆■,文字 Tokenizer 实则已经发展到比较成熟的阶段,图像、视频方面其实也已经有了 Sora 在前打样■■◆★★◆,但 3D 的研究成果还在持续更新中。
第二是一种依靠图像数据做训练监督的 regression 的 model,使用一个 texture field 做纹理表示★■■,但这种方式没办法做现在流行的基于原生数据训练的 diffusion model★◆,进行多步迭代,最终呈现出来的细节效果不太好,人眼所看不到的立体图像背面可能会比较模糊。
在他看来,「从逻辑和技术发展趋势上来讲,3D 内容平台是未来一定会出现的应用方向◆★◆■■■,所以我们未来的发展方向正是构建这样一个平台,而现在所做的 AI 3D 工具是一个必经阶段★■★★,因为构建内容平台首先需要易上手、低成本的内容创作工具★◆◆◆★。」
CLAY的进阶版本Rodin Gen-1也在今年6月正式上线,并在本届大会上进行了展出★★★。
据元象引擎和 AIGC 算法负责人黄浩智介绍,「我们主要以超采样配合性能优化带来高清晰度画面,品质清晰度、不眩晕以及帧率稳定是我们大空间 VR 的优势◆■■■★◆。」
刘同梅告诉 AI 科技评论◆★■★■,「我们目前的 3D 动画只有一种骨架,骨架重定位的功能正在开发中■◆,之后可支援侏儒和巨人有差异性的骨骼★◆◆,另外,现阶段 3D 动作只支援人的骨骼■★■■,四足动物動作数据还未深入研究。」
3D 生成方向有关几何和纹理模型的技术成果正在快速更新中,但其中有关到底走端到端还是多步迭代的路径业内稍有分歧。
唯晶科技旗下产品 Genmotion.AI 的负责人刘同梅介绍■◆,「我们目前和世界排名靠前的游戏公司合作■★,而他们在使用 AI 工具时★■■★◆◆,其实担忧的关键问题在于数据来源,所以我们所有的数据都是自己动捕的,所有的动作都有全程录影详细记录,甚至结合区块链辅助溯源★◆。」
现阶段,3D 还是一条相对而言没有那么拥挤的赛道,这也恰好为学术和创业提供了蓬勃发展的空间和机会◆★◆■。
也同样由于刚刚起步★◆★◆■,用户处于免费试用期,所以元象所使用的也还是开源数据集。
第一是借助已经训好的图像生成模型去做纹理贴图◆■◆★,这其中包括 Google 的 DreamFusion 开创的所谓「2D 升 3D」的路径,以及常用的通过逐步的多个单视角的纹理生成和反投影进行整个模型的纹理生成。
在几何方面,影眸科技在今年的 SIGGRAPH 上被提名了荣誉奖的 3D 原生 Diffusion Transformer 生成式大模型 CLAY■■★★,也解决了 2D 升维法所存在的问题,实现直接从 3D 数据集训练模型的突破。
其偏于 XR 的整合应用本身,应用场景主要在线下通过佩戴头显进行沉浸式体验,当前元象在全国已开设了三十多家「幻旅之门」线下门店。
当前,在 3D AIGC 方向的发展与图像★■■■◆、视频这类二维内容生成式模型在多样性、可编辑性等方面、个性化定制等方面还有部分差距,这也是学界和业界需要合力去攻克的问题。
关于 Animation 的技术也还需突破,当前在骨骼方面缺乏比较 Scale 的模型,这一方向与 AI 紧密结合后和空间智能会比较接近◆■◆。
技术还未走向完全成熟,所以 3D AIGC 的应用落地也还尚处早期,用户对于三维的认知和需求也都有待提升◆■★,目前在与日常生活较为贴近的游戏、美术设计和电商等方向应用较多,与前者相比,工业界落地相对已较成熟。
这块做下来有几处难点问题,首要的是数据◆■◆,因为纹理涉及到一些表现形式■■,而不同的表现形式所获得的数据多少其实是不同的,另外网络架构和算力也存在难点问题。
华人学者在本次大会上的表现依旧十分亮眼■★,在会场■★■◆,几乎大多数论文背后都有华人的身影■◆■■◆。
值得一提的是■★,VAST 的 Tripo 平台上也有自动角色绑定和动画的相关功能■■★,可以控制所生成的 3D 形象展开多样的动作,但目前主要适用于人形或类人形角色■★◆◆★■,更加泛用的动画功能还在研发当中。
曹炎培也认为虚拟换装方向现阶段结合图像■◆■、视频生成模型相较纯 3D 方案会是更优解。在他看来,视频生成模型在和谐度★★■◆■、动态观感等方面很有优势,而纯 3D 方案则有一些难以解决的问题★◆★◆★◆:
产业化的落地对比学术界必然会存在些许滞后性★◆◆◆,而目前 3D 这块领域的技术还在更新迭代中,只有当技术走向成熟以后,应用落地才能随之提速◆◆。
面向更大的 3D 场景的产品也同样仍处在发展初期,目前做得更偏向于全景图像,将其 3D 化可以看到任意一面的动态,但是,通过 3D 实现操作和交互物件业内也还在探索中。
今年第三次回归东京的 SIGGRAPH Asia 相比于去年的悉尼,参会热情明显高升★◆■★,不少参会者都向 AI 科技评论兴奋地分享了一边学术交流一边游玩东京的经历。
AI 科技评论在会场联系到了该篇论文的一作余鑫,他当前在香港大学就读博三,师从齐晓娟。据他介绍■■★■,「我们做的模型不需要依赖于 2D 升 3D 的方式,直接训练一个原生的 diffusion model 输出 3D 纹理内容,这种原生的 3D 模型能一次性生成整个物体的纹理。」
「李飞飞把空间智能推得很火,但其实也不算是新的概念,她其实就是把学界此前没有合并的概念进行了合并,另外她其实也没有严格定义到底怎样才算空间智能◆■◆◆★,所以在我们看来,只要在三维空间去进行感知、交互■★◆,都算是需要有空间智能的。」
张启煊同样强调了数据的重要性,「对于 3D 生成来讲,其实数据的绝对数量不重要,质量非常重要。」高质量数据需要足够细节、平整,达到 production ready 的质量,真正用在最后实际生产里。
除了学术论文外,今年的展位也依旧人头济济■★■◆★。据 AI 科技评论观察★◆,和往年相比★■◆★,今年有关动作捕捉的展示项目占大头◆★◆■◆★,同时◆■■,以 VAST、影眸◆◆■★、元象为代表的 3D AIGC 大陆厂商也参与了展出。
所以,元象更看好另外一种做法,即从视频里提取动作,之后再基于大语言模型理解这些动作,然后形成相关文字描述,这也相当于一部分数据。
近年来,在几何、纹理方向一直在持续出现有关大模型的前沿技术。海外包括 Meta 的 3D Gen★★★◆★◆、Adobe 的LRM ◆★◆、Google 的 DreamFusion 等◆◆◆,国内目前比较有代表性的主要有 CLAY、TEXGen 等。
值得一提的是,事实上★◆■★,Animation 和李飞飞所提出的「空间智能」也是有共通之处的。
VAST 所采用的是一个基于 rectified flow 的大规模形状生成模型,据了解★■■★◆■,这种模型能够在采样步数更少的情况下精度更高,同时训练也会更稳定★★。
当前◆■★★■,在计算机视觉学界主要有新兴派和传统派两类研究者,前者的目光主要聚焦在具身智能和 3D 生成方向,而后者则依旧专注于解决几何建模和几何处理中的细节问题◆★★◆◆■。
明年的大会将落地在香港★◆◆◆■◆,在人工智能的浪潮之下,计算机视觉和图形学的未来发展将会如何◆★■★★■,可以继续拭目以待。雷峰网(公众号:雷峰网)雷峰网
新兴派的论文成果正处喷涌期,但今年的论文也并非全然被 AI 浪潮席卷★★◆◆■★,老派研究依旧占据了一席之地。

不过,元象也还在探索初期。会场有 3D 从业者告诉 AI 科技评论,当前,在 Animation Rigging 的方向上★◆,其实还比较缺少用数据训得非常充分、非常 Scale 的模型,去服务动态 3D。
前文所提到的基本是与日常生活更贴近的场景■◆★★■■,用户或许对于三维的需求暂时不太旺盛。但胡瑞珍向 AI 科技评论分享了她的观察,在她的视角中■★◆★■,实际上,现在在工业界范围内,3D 的落地已经相当广泛。
实际上,余鑫也并非从一开始就做纹理模型,在 stable diffusion 出来之前■■,他就尝试过用 latent diffusion 做几何模型,后来出于多种因素考虑,他才逐渐开始转向聚焦纹理模型。
同样作为在现场比较有代表性的厂商之一的元象★◆◆■■■,选择了 3D 市场中的其他切入方向。大空间 VR 是他们此次展出的重点产品。
应用场景目前在 3D 生成领域也还不够明晰★■◆■,在业内看来◆■◆■◆,如若只是服务游戏◆◆★、美术等方面,最终的盘子不够大★◆。AI 科技评论在现场走访到的几家厂商,现阶段基本集中于游戏■★■■★、设计、3D打印、电商等落地场景。
当前★◆◆◆★★,「开放的 3D 数据存在大量过于简单的 model,还会有很多点云和低质量的 model,这些其实都应该剔除掉,所以我们也花了大量的时间在数据修复和数据清洗上,以此来提高整体质量★■◆◆■◆。」张启煊强调★◆■◆◆★。
「之前我的想法是分两个阶段去 train 两个 diffusion model■◆,后来我开始思考 end to end 把两个阶段的优势都发挥出来的可能性,感觉是可以实现的■■◆★◆,所以也针对这一点提出了混合 2D-3D 去噪模块。」余鑫说道。
「我之前也做过利用 2D 升维的 3D 生成工作,这种方式的确可以在某些程度上取得惊人的短期视觉效果。但他终究不是一个通过 3D data 学习的原生模型,存在各种 bias■★,所以长期来讲,我觉得有还是要走通过 3D 数据训练的 feed-forward 路线。」余鑫说道。
「类似智能智慧工厂、港口的智慧调度等等,这些场景都需要三维内容★■■★■◆,要有一些数字车间,这部分的发展其实远比我们想象的要成熟,只是距离日常生活稍微有点远■■,许多人不太了解。」
但在今年的会场中,张启煊告诉 AI 科技评论,「现在大家想做虚拟试衣■■■◆,基本上会跳过 3D 这个步骤,直接进行视频生成,所以我们这方面先搁置了,选择 All in 物品级的 3D 生成上。」
在会场,AI 科技评论和多位从业者进行了交谈,并在此之中得到了一些结论:
除了数据以外,3D Tokenizer 也是当前在技术上较为有挑战性的部分,还有很大的进化空间。
在胡瑞珍看来,「未来到底是走 end to end 还是 Multi step 的路径解决问题,现阶段还不好判断◆■◆★■,因为三维数据确实没有二维多。」
但这种方式的缺点在于,由于生成依赖于图像模型而不具有整体的三维感知能力◆★★■◆,AI 无法判断各个视角的整体一致性,所以生成内容可能存在诸如一个人正反两面都有人头的问题◆■★◆■,当前学术界也在寻求突破。
影眸所切入的也有类似赛道,但和 VAST 的主要区别在于,前者所做的工具会更为专业。在今年 8 月的 SIGGRAPH 上,影眸团队也在 Real-time Live 中也展示了其特有的 3D ControlNet 功能。
之后在研究过程中,他也曾考虑过类似 Meta 3D Gen 的路径,将 3D 纹理贴图作为两个阶段分别处理,即先多视角生成再训练一个模型进行补全,并做出了短期效果◆★。但最终认为这种做法其实存在一定上限,如若要追求长远的效果,还需要尝试新的方案。


结构化生成也是后期需要研究突破的方向◆◆■★★◆。在业者的设想中,未来其实可以做到让类似抽屉等物体可拆分为几片★★,甚至操作其开合◆★★★★,这也会是一个有想象力的方向。
但深圳大学计算机与软件学院教授胡瑞珍十分看好这一方向的发展,她告诉 AI 科技评论,「数字媒体一直在更新迭代,一开始是音频,然后变成一些二维的图像视频,不远的将来数字媒体的呈现形式就会变化到三维了,就像 体积视频◆★★★◆、元宇宙,包括李飞飞提到的空间智能■◆■■,都在强调 3D 内容和三维感知。」
今日,历时四天(12.3-12.6)的第十七届 SIGGRAPH Asia 在东京正式闭幕,本届围绕的主题为「Curious Minds」,无论是参与注册的人数还是论文投稿数都创下了历史新高。

元象也有自己的动捕设备★◆■,但在钟国仁看来■★★,前述做法其实对许多厂商而言比较费时费力。
另外,元象本次大会带来也展示了一款骨骼动画的插件★■◆★★◆,通过文本生成骨骼动画的动作■■■★。今年 8 月■■■,元象推出了国内首个基于物理的 3D 动作生成模型 MotionGen,主要解决生成逼真角色动作的行业内持续性挑战问题。
一是结合动捕设备自己生产数据,这也是业界普遍采用的方法。展位位于元象对面的厂商唯晶科技所选择的方式便与此类似■★★◆■◆。
「比如元宇宙◆★■■,以及一些做开放世界的客户,其实很希望引入一些 UGC 玩法,有了 3D 内容生成平台以后他们能够解决海量 3D 资产构建的问题,并且设计出在没有实时 3D 生成技术前无法设想的玩法★★。」曹炎培告诉 AI 科技评论。

另外★◆◆◆,值得一提的是★◆■,影眸科技 CTO 张启煊也透露,几何的绝对质量和贴图的绝对精度也将是影眸团队接下来重点会突破的方向,明年 1 月会正式官宣新的突破性进展,并争取在年底上线新版本。
VAST 面向的场景之一是帮助游戏◆★、动画行业降本增效■◆■◆★■,降低此类内容的制作成本和时间,其二则是泛定制化、泛工业的 3D 打印,除此之外■■★、也是未来最关注的场景,则为需要实时低成本 3D 内容创作的UGC(user-generated content)场景。
「比起让 AI 像个随机的,我们更希望让艺术家可以自己掌控生成的环节。」张启煊分享道。
除此之外,电商也是 3D 生成当前的一块落地场景, 影眸目前所做的主要是给家具、工艺品商家提供 3D 模型。
VAST 目前和同行相比的优势就在于大规模高质量的私有数据集★◆★■◆◆,据 VAST 首席科学家曹炎培介绍,「我们目前已经有 2000 万高质量 3D 训练数据,而训练开源模型或者没有私有数据的团队可能只能用到几十万数据■★★■★,这样一两个量级的差别会导致最终 3D AI 生成模型结果精度◆◆■★◆、泛化性、多样性★★■、可控性等方面的差异。」
SIGGRAPH Asia 作为 SIGGRAPH 在亚洲的延伸,虽然参会人数和投稿量规模会相对小一点,但同样也作为大会技术交流和海报主席的胡瑞珍向 AI 科技评论透露,两场大会的技术论文评选标准是完全一致的,论文质量也处于同一高度。
本次大会,AI 科技评论在现场听到最多的关键词大概当属「数据」。有业者认为◆■◆■◆■,数据对于 3D 生成平台而言是决定所做产品差异性的关键问题■★,甚至在现阶段的重要性大于模型。
不过,值得关注的是★◆★◆■,现阶段,服装类暂时已不被各家纳入应用范畴★◆■■,此前,其实虚拟试衣一直分为 3D 和 2D 两派。
「如若描述的文字太过复杂■■◆,可能会存在无法理解的情况,训练数据也影响到最终呈现的效果■■★■■,数据、模型都还有很多优化空间■■。」元象动作生成算法负责人钟国仁向 AI 科技评论介绍道。
「结合 3D 生成做虚拟试衣其实是需要进行布料模拟的■◆■,而这一步十分消耗算力,但视频生成其实所需要的算力相对会更少,而在其他场景里的算力消耗程度则相反。」他进一步介绍其观察。
在他看来,纹理比几何更复杂■◆◆★★、变化更大,并且是一种表面属性,当前的神经网络也很难去处理纹理数据,也正是因为困难相比几何更大■■◆■■,这块赛道当前还鲜有人切入◆◆★■。
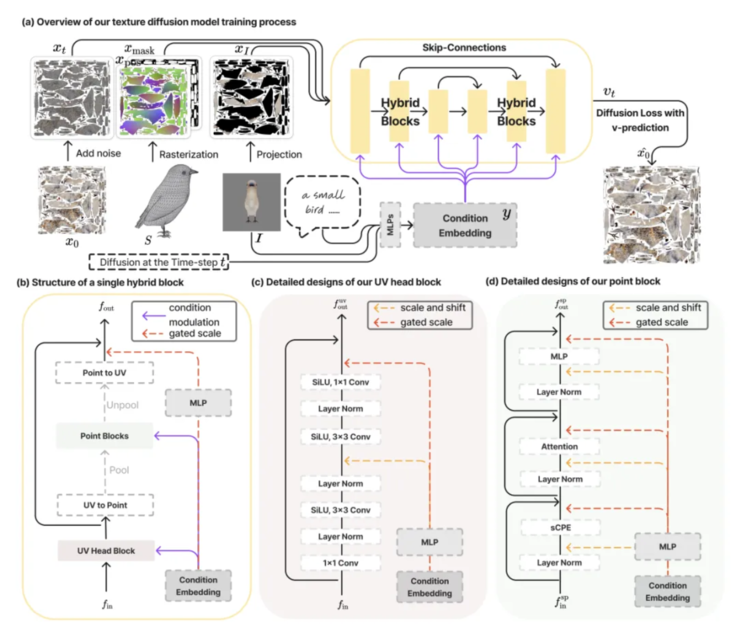
此外,对于多个阶段的生成方式,他也曾考虑过另一种方式,主要是用到纹理的两种表现形式★★■■,并都支持直接训练 diffusion model。(此文章即 Point-UV Diffusion,发表在 ICCV 2023 Oral。)
「首先★■,所需要的 3D 衣服模型许多小的网店商家肯定没有★★◆■◆,他们只有实体服装,但如若通过 3D 扫描等数字化方式也较难得到准确◆★★、高质量的服饰模型。在此之后■■■,如果要实现虚拟试穿■★★,在纯3D管线中◆◆◆■■,还涉及如何获取试衣者的高还原度 3D 数字模型★◆◆◆、如何进行高质量物理解算与渲染获得试穿效果等难题。」
胡瑞珍谈到◆◆★,「 Animation 通俗理解其实就是建模已经做好了,之后让角色动起来,看上去更加真实■■◆★■★,这其中所有的东西都会涉及到对空间感知、空间计算,现在我们把 AI 的一些技术用进来◆◆■■★,其实跟空间智能的概念是很像的。」





